
クローリングってなに?SEOの基本クローラーと自分で行うクローリング方法について
最終更新日:2023/10/26

クローリングとは、Webサイトを検索のデータベースへ登録するために、クローラーというロボット(プログラム)がWebサイトの情報を収集することをいいます。
Googleなどの多くの検索エンジンは、それぞれの検索のデータベースに情報を登録しています。ユーザーが検索キーワードを入力した際にデータベースから検索結果として表示されるのです。
クローリングは、ただ待っていても行われますが、自社のWebサイトをより早く、すべてのページをクローリングしてもらうには、Google Search Consoleを使うのがベストです。
「クローラー」が情報を収集しやすいホームページかどうかを「クローラビリティ」といい、「クローラビリティ」を向上させることはSEOの一貫と考えられています。
本コラムでは、「クローラー」とは何かという基本と「クローリング」の仕組み、自分でクローリングをさせる方法までをご案内します。
【本記事と合わせておすすめの無料SEO資料】
基本的なSEO対策のチェックリストを作成しました。
よろしければご活用ください!
>基本のSEO対策チェックリスト
より上級者向けのノウハウ資料はこちらから。
>中上級者向けSEOセミナー資料
SEOの基礎と記事の書き方はこちらもどうぞ!
>全63ページ!「SEOの基礎と記事コンテンツの作り方」をダウンロードする
目次
1、クローラーとは
- 1-1.クローラーの種類
- 1-2.クローラーが収集するファイルの種類
- 3-1.Google Search Consoleを使う
- 3-1-1.1日にクロールされるページ数
- 3-1-2.1日にダウンロードされるデータ量
- 3-1-3.ページのダウンロード時間
- 4-1.Webサイト全体をクローリングさせる方法
- 4-2.クローリングの巡回を促す
- 4-2-1.4-2-1、Fetch as Googleの使い方
5、まとめ
1、クローラーとは
クローラーとは、Webサイトを検索のデータベースへ登録するためのロボットのことで、Web上を巡回してHTMLファイルやPHPファイルなどを読み込み収集して検索のデータベースに情報を登録しています。
クローラー自体はプログラムになっていてホームページのHTMLに記載されているリンクの情報をたどり、そのホームページがどのような内容なのか、構造なのかを確認しデータベース化していきます。
インターネット上でクローラーはアクセスできるファイルや情報を出来るだけ収集しようとするため、検索されないようにしたい情報はクローラーが入れないように設定しないといけません。
また逆に言えば、Webサイトを新たに作成した際にクローラーはなかなか見つけることが出来ない為、作成した方から見つけしやすくしてあげる必要があります。
新規サイトに関してはクローラーが早く見つけてあげられるような設計、構築、更新を「クローラビリティを高める」と言います。
1-1、クローラーの種類
特に有名で、耳にしたことがあるものはGoogleの「Googlebot」。
他にも多数クローラーは存在しており、Google以外の主な検索エンジンといえば
・bingbot:Bing
・Baiduspider:百度(中国最大の検索エンジン)
・Yetibot:NAVER(韓国の検索ポータルサイト「NAVER」)
などが上げられます。
現在日本国内におけるSEOでは、Googlebotだけを考慮して更新を行えばいいと考えられています。
理由としては日本国内での検索エンジンシェアNo1を誇るYahoo!でもGoogleのシステムを利用しているためになります。
GoogleとYahoo!だけで日本国内の検索エンジンシェアは9割を超えているため、Googleだけについて考えられれば日本国内では上位へ上がってくるようになります。
1-2、クローラーが収集するファイルの種類
クローラーはHTMLファイルなどの情報を読み込みますが、HTML以外のファイルも読み込み収集することが出来ます。
・PHPファイル
・JavaScriptで生成されるリンク
・Flashの中にあるリンク
・WordやPowerPointなどによって作成されたファイル
なども、クローラーは収集してくれます。
上記一覧での共通項は、文字であるという事です。
クローラーはプログラムなので、デザインや画像の美しさなどを理解し、情報として収集することが出来ません。
その為、伝えたい情報は画像化して表現するのではなく、伝えたい情報はテキストで作成しないと情報として集めることが出来ないのです。
2、クローリングの方法
「クローラー」がWebサイト上の情報を収集する作業をクロ―リングといいます。
収集方法はHTMLの中にあるリンクを発見しては、次のページへ進みWebページを循環していきます。
Webの世界に張り巡らされている情報網が蜘蛛の巣のように見え、その蜘蛛の巣を自由に渡り歩くため「スパイダー」と呼ばれることもあります。
この張り巡らされた情報網を自動的に巡回し、膨大な量を収集していきます。
3、クローリングの確認方法
クローラーが一度存在を知ったWebサイトは、リンクをたどることなくクローリングされます。
一度でもクローラーが訪れたサイトは、クローラーが通れる検索エンジンに載る直通の道が出来ます。
どのくらいの頻度で情報収集しているのかはシステムでの自動反映の為これと決まった事はありません。
しかし、「質の高いコンテンツ」「正確に評価されている」サイトであれば検索の上位を狙いやすいと言われています。
また、より多くの頻度で巡回させるためにはWebサイトの更新頻度の高さも関わってきます。
3-1、Google Search Consoleを使う
「Google Search Console」というGoogleが提供している無料ツールがあります。
このツールは、自社で所有しているWebサイトを登録し、ログインするといつ、どのくらいの量がクロールされたのか確認することが出来ます。
確認方法は右側のメニュー内、 クロール>クロールの統計情報 から確認が出来ます。
一日どのくらいクローリングされているのか弊社Webサイトのモノで確認してみましょう。
▼弊社クローリング事例
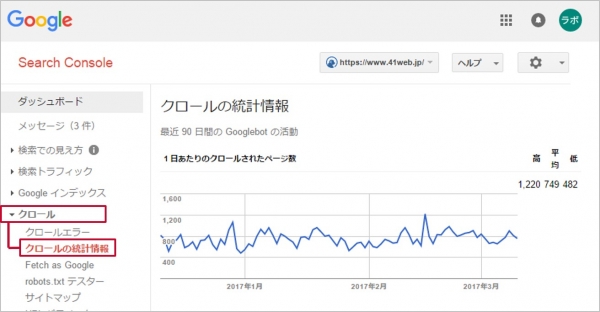
内容の確認を上部から行っていきます。
3-1-1、1日にクロールされるページ数
自社のサイトをクローラーが巡回した回数と、一日に巡回したページの総数が表示されます。
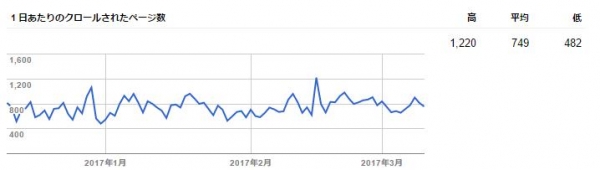
画面右側には、一日のクローリングの最高値、平均値、最低値が表示されます。
クロールされる頻度が上がることはSEO上重要なことです。
3-1-2、1日にダウンロードされるデータ量
クローラーがあなたのサイトをクロールした結果、1日にダウンロードしたデータ量が記録されます。
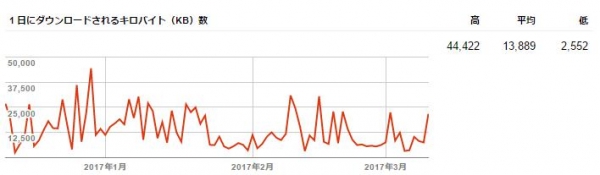
サイトの表示頻度はSEO上好ましくない為、時間がかかっている場合は、一番簡単な方法としてはWebサイト内に入っている画像のサイズ縮小変更(サイズの最適化)を行ってください。
3-1-3、ページのダウンロード時間
クローラーがWebサイトを巡回した結果、ページのダウンロード時間が記録されます。
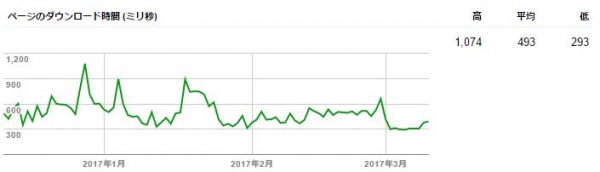
この時間はミリ秒のため、1000分の1秒単位になります。
アクセス過多になる場合はこのページのダウンロード時間がかかるようになります。
処理速度が一定して長い場合は、サーバのスペックの問題になる為、よりダウンロード速度が早くスペックの高いサーバへの変更をお勧めします。
4、クローリングをさせる方法
「Google Search Console」の中でWebサイト全体と、ページごとにクローリングの申請を行う方法があります。
4-1、Webサイト全体をクローリングさせる方法
「Google Search Console」へ入り、右側のメニューバー内クロール>サイトマップを選択します。
右上に「サイトマップの追加/テスト」というボタンがありますのでクリックします。
これで「sitemap.xml」をインポートします。
(弊社CMSBlueMonkeyをご利用の企業様は、ドメインの後に「sitemap.xml」を挿入し、送信してください。)
▼「sitemap.xml」例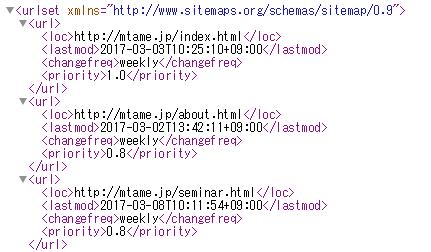
新規ドメインのWebサイトは上記を利用すると、早くにクローリングされるようになります。
また、sitemap.xmlがサイト内のどこにあるか把握されていない方、作成方法が分からない方は、無料で作れるツールもありますので、そちらを利用して作成してください。
▼サイトマップを作成-自動生成ツール「sitemap.xml Editor」
http://www.sitemapxml.jp/
作成後はWebサイトのあるサーバへアップロードし、送信してください。
「sitemap.xml」には、
・更新されたページのURL
・いつ更新されたのか
・更新頻度はどの程度なのか
・クローリングの優先度はどの程度か
が記載されています。
実はこれらの情報はGoogleから重要視されてませんが、「sitemap.xml」があれば検索エンジンは記載されたURLを把握し、クローリングをしに来てくれます。
4-2、クローリングの巡回を促す
「Google Search Console」へ入り、右側のメニューバー内クロール>Fetch as Googleをクリックします。
「Fetch as Google」には
・アクセス出来るかどうかを確認する機能
・ページを正しくレンダリングするのかを確認する機能
・インデックス登録を申請する機能
の3つの機能があります。
「Fetch as Google」で申請すると、なかなかインデックスされなかったWebページを申請することが出来、早期にクローリングされます。
もし、申請してもインデックスされない場合は、ページ自体にインデックスされない設定があるかどうかを確認してください。
4-2-1、Fetch as Googleの使い方
申請したいページのURLを入力します。
例えば、「blog」ページ以下のサイトを確認したい場合は、ドメイン以降つまり「blog/」をテキストボックスへ入力します。
その後、利用するクローラーを選択します。(デフォルトでは「PC」になっています)
ページのインデックスを申請する場合には「取得」ボタンをクリックします。
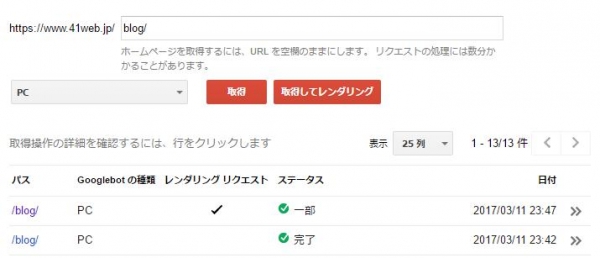
また、大幅にCSSやJavaScriptのファイルを変更した後は、クローラーがアクセスでき、問題なくページが表示されるかどうかを確認する「取得してレンダリング」をクリックします。
「取得」「取得してレンダリング」のボタンをどちらかクリックしても、画面下部にインデックスされたかどうかの結果が表示され、確認したい行をクリックすると詳細が表示されます。
取得後、結果一覧画面に「インデックスに送信」というボタンが表示されます。
このボタンをクリックするとそのページをインデックスを申請することが出来ます。
インデックスに送信するをクリックすると「このURLのみをクロールする」「このURLと直接リンクをクロールする」の2種類が選択できるようになります。
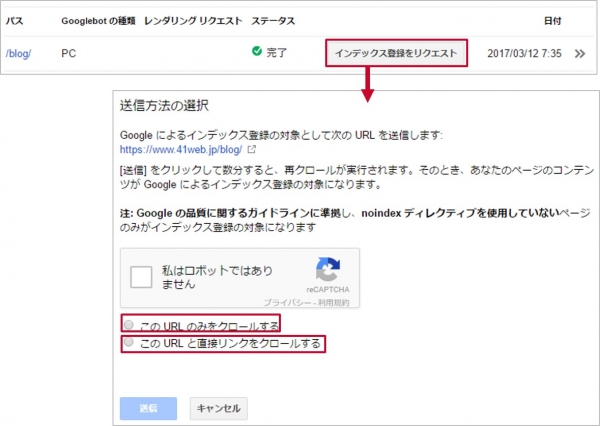
そのページのみインデックス申請されるのであれば、「このURLのみをクロールする」を行い、取得したページからリンクされている複数ページをまとめて行う場合は「このURLと直接リンクをクロールする」を選択してください。
ただ、「このURLのみをクロールする」は月500回使用できますが、「このURLと直接リンクをクロールする」は月に10回までの利用制限がありますので、注意してください。
5、まとめ
以上が、クローラーについてとクローリングされる方法でした。
コンテンツを更新してもなかなか検索に上がってこないなと思われた方はもしかするとクローリングされていない可能性もありますので、一度確認されてはいかがでしょうか。
「Google Search Console」Webサイトへ流入するユーザーを確認するためのツールとして使用されることが多いですが、一度自社のWebサイトがどれだけクローリングされ、インデックスされているのかを知るにはもってこいのツールです。
もしまだ利用されていない企業様がいらっしゃいましたら、「Google Search Console」の登録をお勧めします。
登録の手順は下記にまとめておりますので、ご確認ください。
■SEO対策の基本!ウェブマスターツールから名称変更したサーチコンソールが便利な理由
【SEO関連記事】
>SEOを基本から解説!最低限抑えたい施策から無料ツールまで
>コアウェブバイタル(Core Web Vitals)とは?導入時期や意味、確認方法などを解説!
>YMYLとは?該当ジャンルとEATとの関連性、SEO視点での対策方法まで!
>E-A-Tとは?SEOでの重要性と対策まとめ
SEOのキーワード選定の手法まとめ!お役立ちツールや無料で使えるサイトまで!







 .png)






